


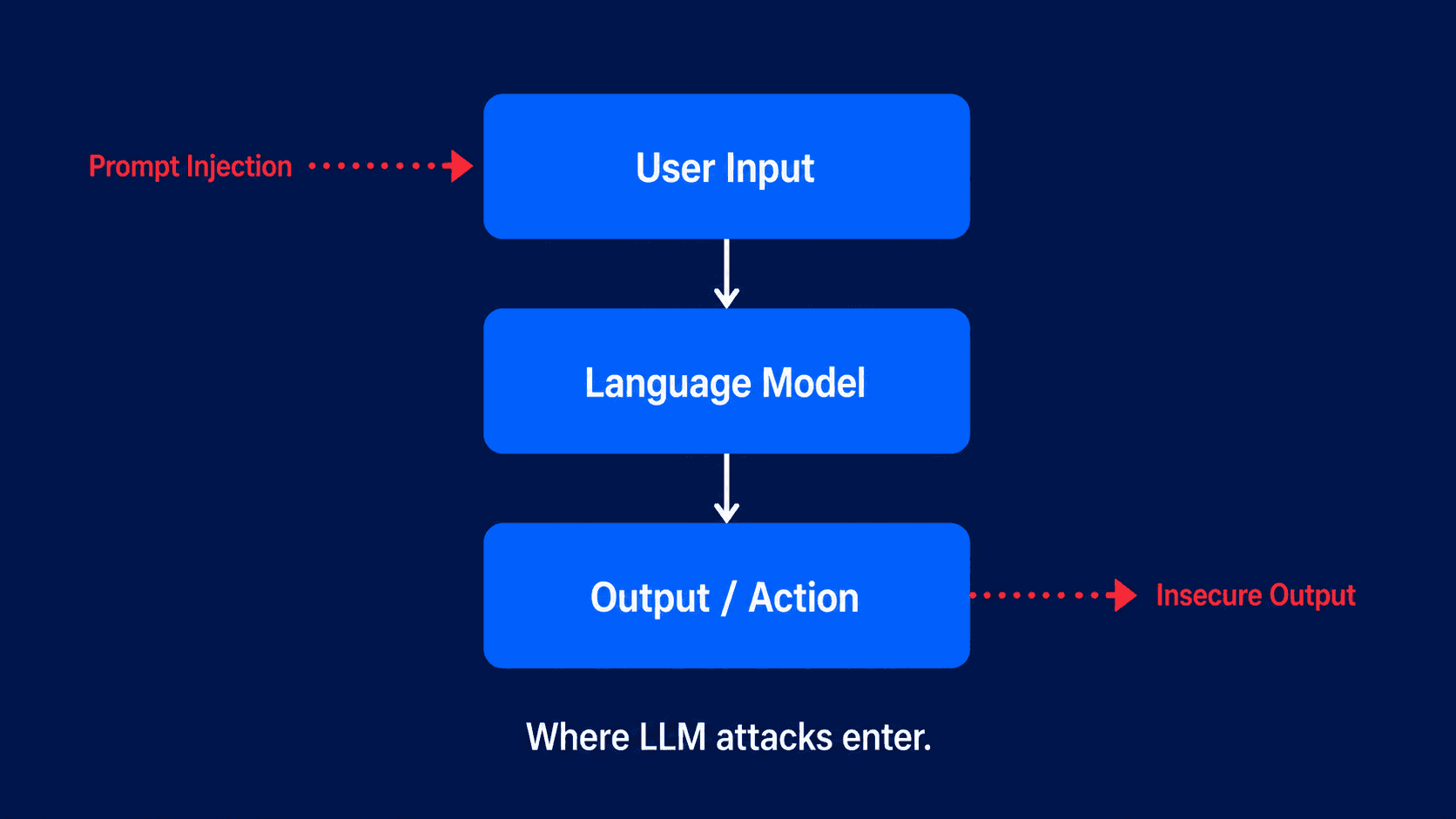
Most security teams know how to test a web app. They know what SQL injection looks like. They know how to test for broken authentication. But when a company ships a product built on top of a large language model, all of that familiar territory disappears. The attack surface is different. The failure modes are different. And in 2026, attackers have already figured out how to exploit them.
This is what LLM penetration testing is about. It is not a theoretical discipline. It is a real, structured testing process that security teams and founders need to understand before they hand a language model product to real users.
Think your AI product is secure because it has guardrails? That is usually the first assumption that breaks under pressure.
If your product uses a language model to process user input, generate content, retrieve data, or take any kind of action, it has an attack surface. That attack surface needs to be tested. Waiting until after a breach is not a strategy.
Ready to see exactly where your LLM product is exposed? Talk to the Capture The Bug team: capturethebug.xyz/Services/penetration-testing.
What Makes LLM Products Different to Test
When Capture The Bug tests a traditional web application, the scope is well-defined. There are endpoints, authentication flows, database queries, and session management. The OWASP Top 10 gives a reliable map of where to look.
Language model products do not work that way. The input is natural language. The output is generated, not retrieved. And the logic that determines what the model will or will not do is probabilistic, not deterministic.
This means a simple rule like “refuse requests about X” can be bypassed not by exploiting a coding error, but by crafting a prompt that leads the model to a different conclusion through conversational framing. That is not a vulnerability in the traditional sense. It is a property of how these systems reason, and it is exploitable.
The OWASP Top 10 for LLM Applications, first published in 2023 and updated since, provides the clearest public framework for understanding this space. It covers prompt injection, insecure output handling, training data poisoning, model denial of service, sensitive information disclosure, and several other categories specific to language model products. Most security teams have not worked through this list methodically. Most founders have not read it at all.
The Attack Patterns That Actually Show Up in Testing
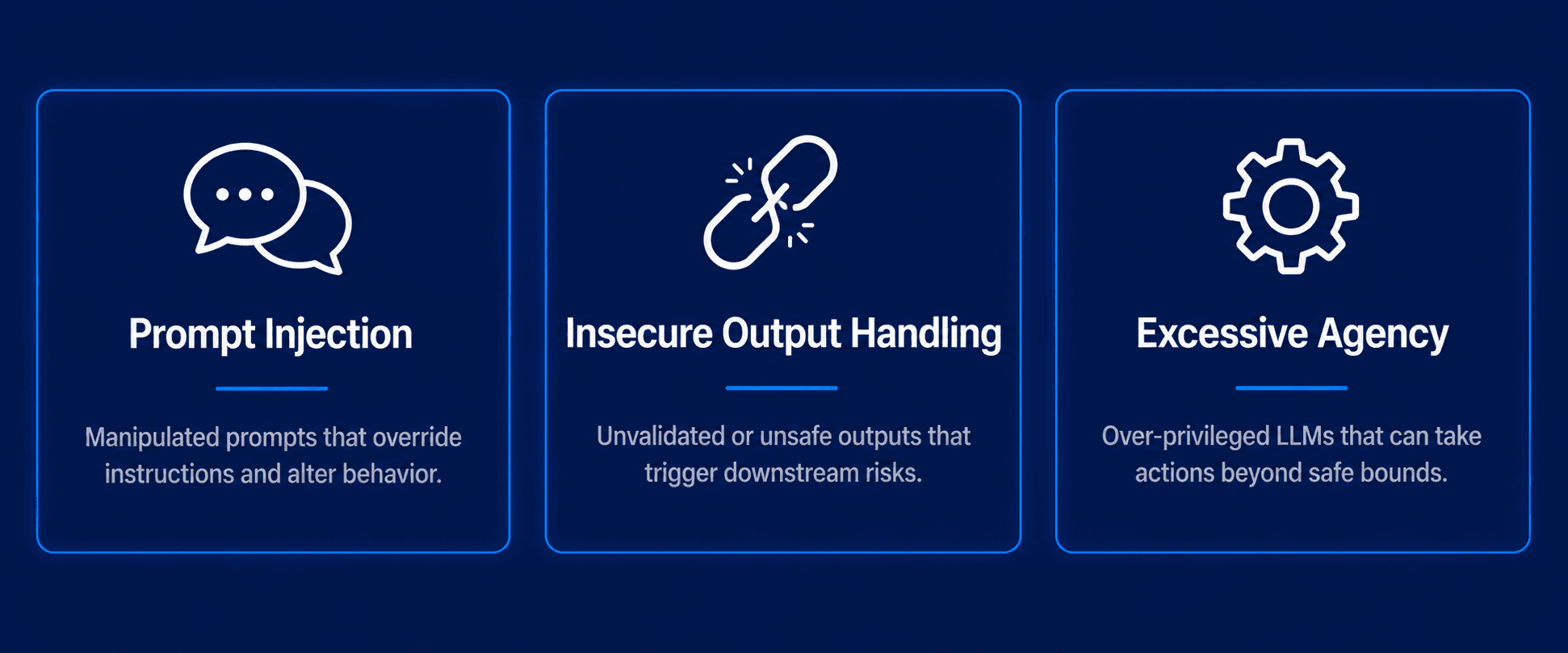
Capture The Bug works with SaaS companies and fintech teams that are building on top of large language model infrastructure. The vulnerabilities that appear most consistently in real testing engagements fall into a few categories:
- Prompt injection is the one that surprises teams the most. If your product takes user input and passes any part of it to a language model, an attacker can attempt to override your system prompt by embedding instructions inside that input. This is especially common in products that use LLMs to process documents, summarise content, or handle customer queries. An attacker submits a document or message containing hidden instructions, and the model follows them.
- Insecure output handling is the second area where products regularly fail. Teams assume that because the model generates text, the output is safe to render. It is not. If your application takes LLM output and passes it to another system, whether that is a code interpreter, a browser, a database query builder, or an email client, the output needs to be treated like untrusted input. It rarely is.
- Excessive agency is the third pattern. As more products give language models the ability to take actions, call APIs, execute code, or retrieve external data, the blast radius of a compromised prompt grows significantly. A model that can only generate text has limited damage potential. A model that can send emails, modify records, or query internal systems needs to be tested with the same rigour as any privileged user account.
What LLM Penetration Testing Actually Involves
This is not about running a checklist. LLM penetration testing is a structured attempt to break your product by thinking like an attacker who understands how language models work.
In practice, that means a testing team works through your product's specific implementation:
- They look at how your system prompt is structured, what information it contains, and whether that information can be extracted through carefully designed queries.
- They test whether your input filtering can be bypassed through encoding, language switching, roleplay framing, or token manipulation.
- They test your output pipeline. They check whether the model can be made to produce content that your application passes downstream without sanitisation.
- They look at what happens when the model is given conflicting instructions from your system prompt versus user input.
- They test your agentic components if you have them. If your product uses a language model to take actions, a skilled tester will attempt to manipulate those actions through the model's input channels.
- They look at data exposure. Language models trained on proprietary data, or given access to sensitive context at runtime, can sometimes be prompted to reveal that information. This needs to be tested before your product reaches users.
For companies pursuing SOC 2 Type II, ISO 27001, or compliance with emerging AI security frameworks, LLM penetration testing is increasingly part of what auditors expect to see documented.
Your Last Pentest Is Already Out of Date
Every week you ship without continuous testing is a week a vulnerability goes unseen. See what Capture The Bug finds in your first engagement.
Why This Cannot Be Handled with Standard Web Application Testing
A traditional penetration test is valuable. It should still happen. But it will not catch LLM-specific vulnerabilities because the testing methodology does not account for how language models process and respond to input.
Standard scanners do not know how to craft adversarial prompts. They do not understand that the same input delivered in French, wrapped in a fictional scenario, or split across multiple messages might produce a different model response than the same input delivered directly. That kind of testing requires testers who understand both the security domain and how these systems behave.
This is also why automated scanning alone is not sufficient for language model products. The attack surface includes the semantic meaning of input, not just its syntactic structure. Human testers who can reason about language model behaviour are a core part of an effective LLM security engagement.
What to Do Before You Get Tested

The companies that get the most value from LLM penetration testing are the ones that come in with a clear picture of their own system. Before engaging a testing team, it helps to document:
- Your system prompt structure.
- All the external data sources your model has access to.
- Every tool or API the model can call.
- The logic that sits between user input and model invocation.
If your product passes user input to the model without any processing, that is worth noting. If your product post-processes model output before displaying it or passing it elsewhere, that is also worth documenting.
The clearer the picture, the more efficiently a testing team can focus on the highest-risk areas rather than spending time mapping your architecture.
The Business Case for Testing Before You Ship

A language model vulnerability that reaches production is not just a technical problem. It is a customer trust problem. If a user can manipulate your product into doing something it should not do, or into revealing information it should not reveal, that story travels quickly.
For SaaS companies at Series A and beyond, a security incident involving your core product is the kind of event that appears in investor conversations for years. For fintech companies, it can trigger regulatory scrutiny. For any company with enterprise customers, it almost certainly affects renewals.
The cost of an LLM penetration testing engagement is a fraction of what a single well-publicised incident costs. The companies that understand this do not treat LLM security testing as optional.
Capture The Bug is a CREST-certified penetration testing company working with SaaS and fintech teams across Australia, New Zealand, and the United States. The team has experience testing language model products across a range of architectures and implementation patterns.
For teams building products on language model infrastructure, a structured security review before wider release is not just good practice. It is the difference between finding the problem yourself and having someone else find it for you.
Explore the full range of security testing services: capturethebug.xyz/Services/penetration-testing
Your AI product is only as secure as the assumptions you have tested. Claim your free security consultation and find out where the gaps are before your users do. Claim your credit and book a consultation: capturethebug.xyz/Claim-Credit.
Plan Your Annual Pentesting Strategy the Right Way
Learn how modern SaaS companies structure pentesting across the year to reduce risk, stay compliant, and avoid last-minute panic before audits.

Frequently Asked Questions
What is LLM penetration testing?
LLM penetration testing is a structured security engagement designed to find vulnerabilities specific to products built on large language models. It covers prompt injection, insecure output handling, data exposure, and excessive agency in agentic systems. Standard web application testing does not cover these vulnerabilities.
Why can't a traditional pentest cover LLM vulnerabilities?
Traditional penetration testing methods were built for deterministic systems. Language model products process natural language input and generate probabilistic output. The attack patterns that apply, such as prompt injection and roleplay-based bypass techniques, require testers who understand how these models reason and respond. A standard scan will not find them.
What does OWASP say about LLM security?
OWASP publishes a dedicated Top 10 list for LLM applications covering categories including prompt injection, insecure output handling, training data poisoning, model denial of service, and sensitive information disclosure. It is the most widely referenced public framework for this domain.
Is LLM security testing required for compliance frameworks like SOC 2 or ISO 27001?
Compliance requirements are still catching up to language model products. However, for companies pursuing SOC 2 Type II or ISO 27001, auditors increasingly ask about how AI-powered features are tested and what documentation exists. Having a formal LLM penetration testing engagement on record strengthens your compliance posture.
How is Capture The Bug qualified to test LLM products?
Capture The Bug is a CREST-certified penetration testing company with experience testing SaaS and fintech products built on language model infrastructure. CREST certification means the testing methodology and team qualifications meet recognised international standards.
What should a company prepare before an LLM penetration test?
Before the engagement, document your system prompt, every external data source the model can access, every API or tool the model can call, and how user input reaches the model. The more context the testing team has, the more efficiently they can focus on the highest-risk components of your specific implementation.


